Getting ready for machine learning - cleaning up free NHL game and odds datasets
Before beginning any feature engineering or ML, it’s necessary to clean up the data first. In this article we work through a real-life example
I recently read The Everything Guide to Sports Betting by Josh Appelbaum. For each major sport, including the NFL, the book describes strategies to try and follow the ‘smart money’ and bet against the public. For the NFL in particular, the author explains that the majority of money comes from bets on the spread, rather than money line, over-under, or prop bets. Furthermore, it’s typically profitable to bet against the public, who tend to overvalue home teams, favourites, and teams that have generally performed well the last few games. Intra-division games in particular are hard to predict as underdogs tend to over-perform in these games.
Fortunately, the NFL dataset from Kaggle that I previously leveraged contains historical spread information. And just as important, it also specifies the home/away teams, when the game was played, and the final result of the game. This provides me enough data to calculate each team’s success the last few games. I can also infer if the game was intra-divisional by maintaining a static map of teams within divisions.
As always the full boilerplate and Jupiter notebook is available here.
First, I drop any columns that are not relevant or inconsistent. I also drop 2021 games as they haven’t happened yet, and all years prior to 2010 as I tend to find that older games have less predictive value.
global_df = pd.read_csv("nfl_games_and_bets.csv")
global_df = global_df.drop(global_df[global_df.schedule_season == 2021].index)
global_df = global_df.drop(columns=['stadium','weather_temperature', 'weather_wind_mph','weather_humidity','weather_detail'])
global_df = global_df.drop(global_df[global_df.schedule_season < 2010].index)
Then, I needed to clean up the data and keep it consistent by performing the following actions:
# Account for team moves
old_to_new_team_name = {"San Diego Chargers": "Los Angeles Chargers", "St. Louis Rams": "Los Angeles Rams", \
"Washington Redskins" : "Washington Football Team", "Oakland Raiders": "Las Vegas Raiders"}
global_df = global_df.replace({"team_away": old_to_new_team_name}).replace({"team_home": old_to_new_team_name})
# Maintain consistency between favourite and team name columns
short_form_to_team_name = {"GB": "Green Bay Packers", "HOU": "Houston Texans", "KC": "Kansas City Chiefs", "BUF": "Buffalo Bills", \
"TEN": "Tennessee Titans", "NO": "New Orleans Saints", "SEA": "Seattle Seahawks", "MIN": "Minnesota Vikings", \
"TB": "Tampa Bay Buccaneers", "LVR": "Las Vegas Raiders", "BAL": "Baltimore Ravens", "LAC": "Los Angeles Chargers", \
"IND": "Indianapolis Colts", "DET": "Detroit Lions", "CLE": "Cleveland Browns", "JAX": "Jacksonville Jaguars", "MIA": "Miami Dolphins", \
"ARI": "Arizona Cardinals", "PIT": "Pittsburgh Steelers", "CHI": "Chicago Bears","ATL": "Atlanta Falcons", "CAR": "Carolina Panthers", \
"LAR": "Los Angeles Rams", "CIN": "Cincinnati Bengals", "DAL": "Dallas Cowboys", "SF": "San Francisco 49ers", "NYG": "New York Giants", \
"WAS": "Washington Football Team", "DEN": "Denver Broncos", "PHI": "Philadelphia Eagles", "NYJ": "New York Jets", "NE": "New England Patriots"}
team_name_to_short_form = {value: key for key, value in short_form_to_team_name.items()}
global_df = global_df.replace({'team_away': team_name_to_short_form}).replace({"team_home": team_name_to_short_form})
The data frame now looks like
schedule_date schedule_season schedule_week schedule_playoff team_home score_home score_away team_away team_favorite_id spread_favorite over_under_line stadium_neutral
7507 9/9/2010 2010 1 False NO 14.0 9.0 MIN NO -5.0 49.5 False
Next, I built a mapping of teams to their divisions, and created two new helper columns to track the division of each team for each game. I used the data from both those columns to determine if the game was intra-divisional. I then dropped the division columns as they were no longer needed.
# AFC = A, NFC = N
# West = W, etc etc
team_to_division = {"ARI": "NW", "LAR": "NW", "SF": "NW", "SEA": "NW", "CAR": "NS", "TB": "NS", "NO": "NS", "ATL": "NS", \
"GB": "NN", "CHI": "NN", "MIN": "NN", "DET": "NN", "WAS": "NE", "DAL": "NE", "PHI": "NE", "NYG": "NE", \
"TEN": "AS", "HOU": "AS", "IND": "AS", "JAX": "AS", "BUF": "AE", "MIA": "AE", "NE": "AE", "NYJ": "AE", \
"BAL": "AN", "PIT": "AN", "CLE": "AN", "CIN": "AN", "LVR": "AW", "DEN": "AW", "KC": "AW", "LAC": "AW"}
global_df2 = global_df
global_df2['home_division'] = global_df2.apply(lambda row: team_to_division[row.team_home], axis=1)
global_df2['away_division'] = global_df2.apply(lambda row: team_to_division[row.team_away], axis=1)
global_df2['intra_division'] = global_df2.apply(lambda row: row.home_division == row.away_division, axis=1)
global_df2 = global_df2.drop(columns=['home_division', 'away_division'])
Then, in order to track each team’s point differential over the last 1 and 3 games. Choosing 1 and 3 games is a bit arbitrary, but I made this choice as the last team’s performance weights heavily on the minds of bettors, and the last 3 games in a season as short of the NFL is a close analog to power ranking. This first iteration does not account for bye weeks, or new seasons, it simply carries over performance from whatever the last game was. I couldn’t figure out a way to do this natively with pandas/numpy, instead having to loop over the columns, so if you have a better way please feel free to contact me.
# Create auxillary columns to make calculations easier
global_df3 = global_df2
global_df3['home_point_diff'] = global_df2.apply(lambda row: row.score_home - row.score_away, axis=1)
global_df3['away_point_diff'] = global_df3.apply(lambda row: row.score_away - row.score_home, axis=1)
global_df3['home_spread'] = global_df3.apply(lambda row: row.spread_favorite * -1 if row.team_favorite_id == row.team_away else row.spread_favorite, axis=1)
team_to_games = {}
# Get last one result
for index, row in global_df3.iterrows():
# Update the mapping
if row.team_home not in team_to_games:
team_to_games.update({row.team_home : deque([0,0,0])})
if row.team_away not in team_to_games:
team_to_games.update({row.team_away : deque([0,0,0])})
last_games = team_to_games.get(row.team_home)
home_last_3 = last_games[0] + last_games[1] + last_games[2]
home_last_1 = last_games[0]
last_games.pop()
last_games.appendleft(row.home_point_diff)
last_games = team_to_games.get(row.team_away)
away_last_3 = last_games[0] + last_games[1] + last_games[2]
away_last_1 = last_games[0]
last_games.pop()
last_games.appendleft(row.away_point_diff)
global_df3.at[index, 'home_last_3'] = home_last_3
global_df3.at[index, 'away_last_3'] = away_last_3
global_df3.at[index, 'home_last_1'] = home_last_1
global_df3.at[index, 'away_last_1'] = away_last_1
My data frame is now:
schedule_date schedule_season schedule_week schedule_playoff team_home score_home score_away team_away team_favorite_id spread_favorite over_under_line stadium_neutral intra_division home_point_diff away_point_diff home_spread home_last_3 away_last_3 home_last_1 away_last_1
10441 1/17/2021 2020 Division True KC 22.0 17.0 CLE KC -8.0 56.0 False False 5.0 -5.0 -8.0 -11.0 6.0 -17.0 11.0
Next, I dropped some columns that I no longer need, particularly those that will cause data leakage (eg the actual score values). I also created a new column ‘home_team_covered’ for use in the correlation matrix.
global_df_final['home_team_covered'] = global_df_final.apply(lambda row: row.home_point_diff + row.home_spread > 0, axis=1)
global_df_final_no_drop = global_df_final
global_df_final = global_df_final.drop(columns = ['schedule_date', 'schedule_week', 'team_home', 'score_home', 'score_away', 'team_away', \
'team_favorite_id', 'spread_favorite', 'away_point_diff'])
# Correlation
corr = global_df_final.corr()
plt.figure(figsize=(20,20))
ax = sns.heatmap(
corr,
vmin=-1, vmax=1, center=0,
cmap=sns.diverging_palette(20, 220, n=200),
square=True
)
ax.set_xticklabels(
ax.get_xticklabels(),
rotation=45,
horizontalalignment='right'
)
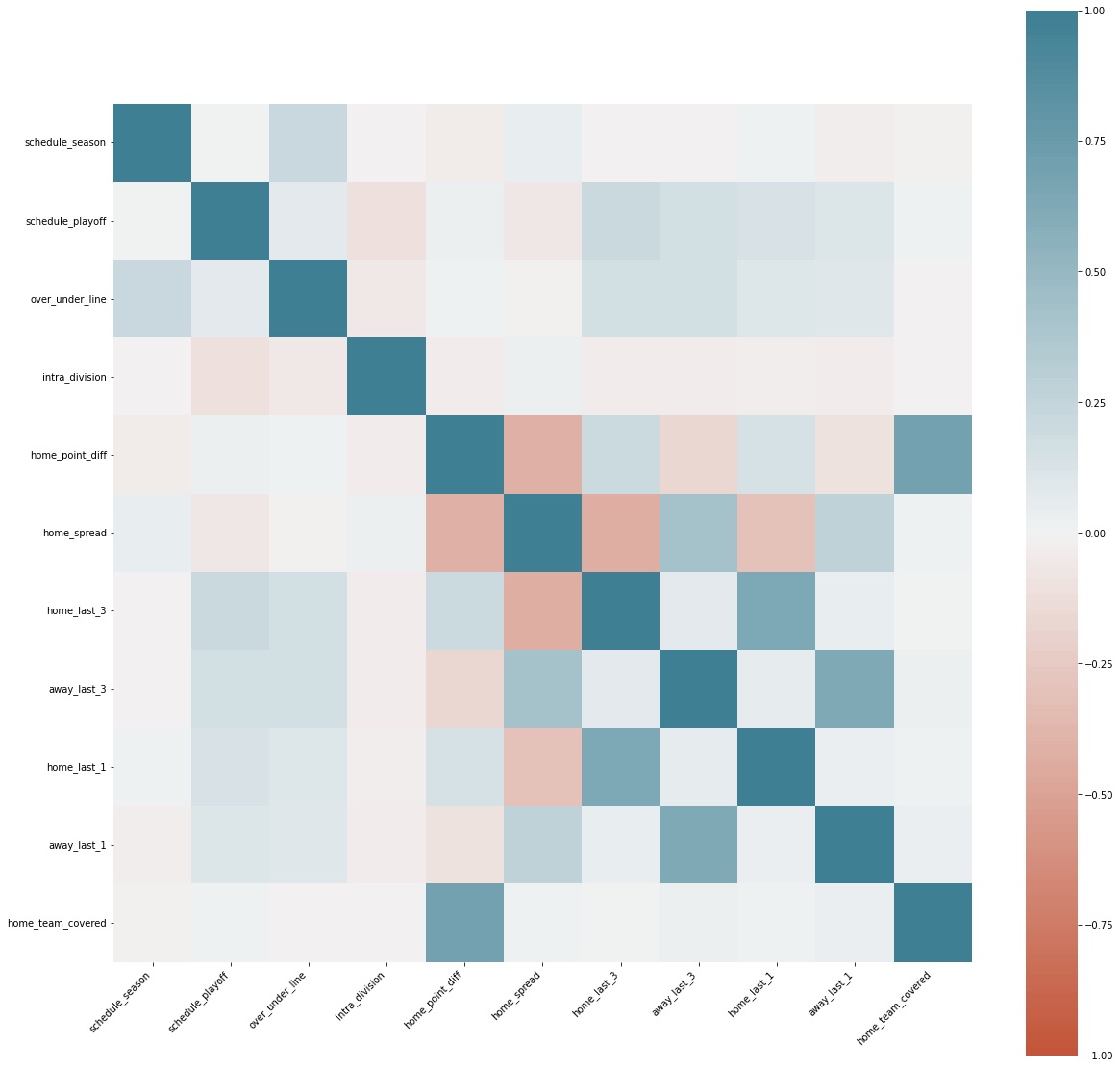
As we can see in the correlation matrix, the ‘home_team_covered’ doesn’t correlate much with anything, with the exception of the ‘home_point_diff’ but that’s due to data leakage (and I drop the ‘home_team_covered’ column next to avoid this issue). Instead, it can be seen that away_last_1, and away_last_3, schedule_playoff, and home_spread have a small positive correlation to the home team covering the spread. This indicates a few things
Lastly, using a GradientBoostingRegressor with GridSearchCV to optimize the hyperparameters, I used the dataframe to predict a new ‘home_point_diff’ column, which is how much the home team is predicted to win by.
train_data = global_df_final.drop(['home_team_covered', 'home_point_diff'], axis=1)
target_label = global_df_final['home_point_diff']
n_features = train_data.shape[1]
x_train, x_test, y_train, y_test = train_test_split(train_data, target_label, test_size = 0.30)
parameters = {
"n_estimators":[5,50, 100],
"max_depth":[1,3,5,7,9],
"learning_rate":[0.01,0.1,1]
}
def display(results):
print(f'Best parameters are: {results.best_params_}')
print("\n")
mean_score = results.cv_results_['mean_test_score']
std_score = results.cv_results_['std_test_score']
params = results.cv_results_['params']
for mean,std,params in zip(mean_score,std_score,params):
print(f'{round(mean,3)} + or -{round(std,3)} for the {params}')
gbc = ensemble.GradientBoostingRegressor()
cv = GridSearchCV(gbc,parameters,cv=5)
cv.fit(x_train, y_train)
0.143 + or -0.028 for the {'learning_rate': 0.1, 'max_depth': 3, 'n_estimators': 50}
I append the predicted column, called predicted_diff, to the original data frame (without dropped columns) to get a final version with the actuals vs predicted.
train_data2 = global_df_final.drop(['home_team_covered', 'home_point_diff'], axis=1)
target_label2 = global_df_final['home_point_diff']
y_pred_full = cv.predict(train_data2)
global_df_final_no_drop["predicted_diff"] = y_pred_full
schedule_date schedule_season schedule_week schedule_playoff team_home score_home score_away team_away team_favorite_id spread_favorite ... intra_division home_point_diff away_point_diff home_spread home_last_3 away_last_3 home_last_1 away_last_1 home_team_covered predicted_diff
7507 9/9/2010 2010 1 False NO 14.0 9.0 MIN NO -5.0 ... False 5.0 -5.0 -5.0 0.0 0.0 0.0 0.0 False 5.083362
Feature importance of the model is the following:
Weight Feature
0.2850 ± 0.0172 home_spread
0.0002 ± 0.0009 schedule_season
0 ± 0.0000 away_last_1
0 ± 0.0000 home_last_1
0 ± 0.0000 away_last_3
0 ± 0.0000 stadium_neutral
0 ± 0.0000 over_under_line
0 ± 0.0000 schedule_playoff
-0.0004 ± 0.0005 intra_division
-0.0015 ± 0.0052 home_last_3
Then, I attempted to backtest the solution. The idea is to start with $100 and assume even -110 odds for any bet. Therefore, on each win we’d win $2.73, and on each loss we’d lose the full $3. Additionally, we are going to be comparing the actual point spread to our predicted point difference. If it differs by some threshold, we can be confident in our model and bet appropriately. For example, if the home team is favoured by -3, but the model predicts the away team will win by 2 points, the difference in the predicted spread vs our model is +5 points favouring the away team, so we’ll bet on the away team as long as our threshold is 5 or greater. After playing around, I left the threshold as 2.
money = 10000
won = 0
loss = 0
push = 0
for row in global_df_final_no_drop.itertuples():
if row.predicted_diff + row.home_spread > 2:
print(row)
if row.home_point_diff + row.home_spread > 0:
money = money + 273
won += 1
elif row.home_point_diff + row.home_spread == 0:
push +=1
else:
money = money - 300
loss += 1
if row.predicted_diff + row.home_spread < -2:
print(row)
if row.away_point_diff - row.home_spread > 0:
money = money - 300
loss += 1
elif row.away_point_diff - row.home_spread == 0:
push +=1
else:
money = money + 273
won += 1
print (money)
print (won)
print (loss)
print (push)
Ending money: 38.41
Wins: 217
Losses: 218
Pushes: 30
This is nearly dead-even in terms of wins/losses, but because of the juice that means we lose $61.59 from our original $100 investment which isn’t what we want. After playing around with the numbers a bit, I wasn’t able to find a value that appreciably changed the win/loss ratio in a positive direction.
The first iteration of the model looks at past performance, the current spread, and if games are within divisions. Unfortunately, the model is not predictive enough to make money. However, this is just the first iteration of the model, and I was able to identify some interesting correlations via the correlation matrix. We’ll continue to explore this backtesting in a future article.
Before beginning any feature engineering or ML, it’s necessary to clean up the data first. In this article we work through a real-life example
Discovering several profitable trends that consistently produce positive returns yearly
Leveraging historical performance and spread data to predict what team will cover the spread
昨日はカナダの選挙でした。人気ではありませんでした。
Comparing at the over/under line from 2010 with weather, team ratings, weeks, etc
A review of Matt Rudnitsky’s ‘Smart Sports Betting: How to Shift from Diehard Fan to Winning Gambler’
64% percent of stocks underperform the market and only 6.1% will outperform by 500%+. What makes these outperformers unique?
Using standard QB stats from 2016-2019, teammate ratings, and strength of schedule to predict 2020 fantasy points.
Using standard QB stats from 2016-2019 to compare predicted 2020 fantasy points vs actual performance.
雪が降っていて、桜はアイスクリームみたい
来週、ユダヤの祝日のハヌカーです。
毎年、北米で人気のゲームFantasy Footballをプレイしています。
Available on iOS, Android, BlackBerry, and Web, Red Sea Rescue is a passover themed game using tilt controls to avoid obstacles.
EZ4X is a graphical, automated forex paper trader that allows users to choose techincal indicators and risk tolerance to automatically execute trades on a cu...